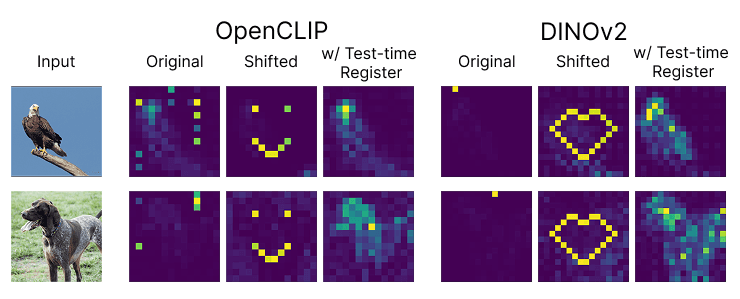
Vision Transformers Don't Need Trained Registers
Nick Jiang*, Amil Dravid*, Alexei Efros, Yossi Gandelsman
NeurIPS 2025 (Spotlight - top 3% of submissions)
paper | project page | code | X thread
TLDR: we find and remove a sparse mechanism that causes attention sinks in ViTs, improving general performance.
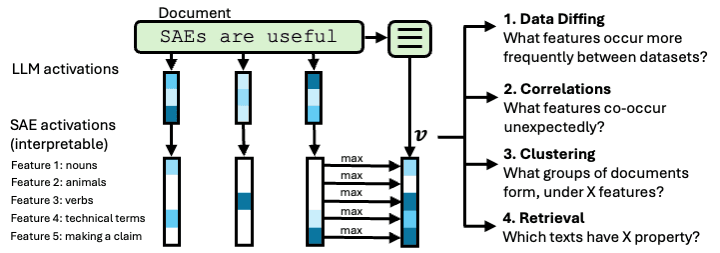
Interpretable Embeddings with Sparse Autoencoders: A Data Analysis Toolkit
Nick Jiang*, Xiaoqing Sun*, Lisa Dunlap, Lewis Smith, Neel Nanda
NeurIPS Mech Interp Workshop 2025 (Spotlight)
paper | project page | code | X thread
TLDR: we show that sparse autoencoders outperform baselines on four data analysis tasks and find surprising model behaviors by analyzing training data and outputs.
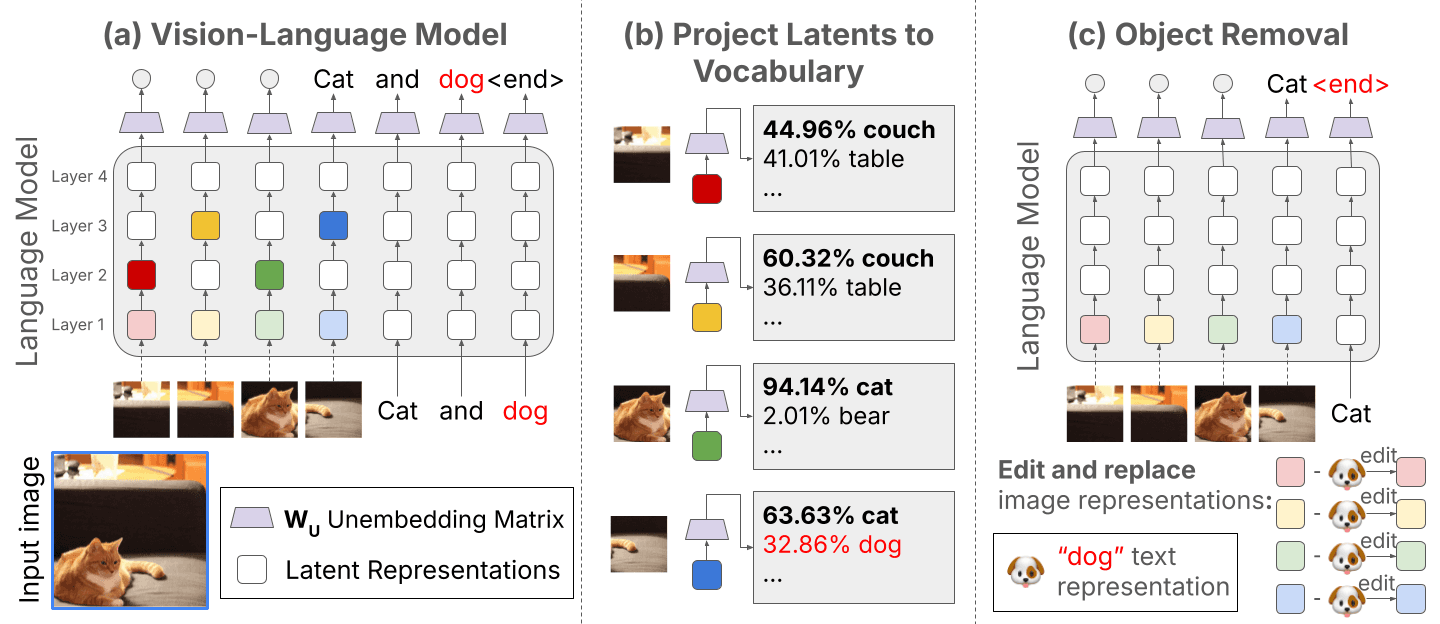
Interpreting and Editing Vision-Language Representations to Mitigate Hallucinations
Nick Jiang*, Anish Kachinthaya*, Suzie Petryk, Yossi Gandelsman
ICLR 2025
TLDR: we use logit lens to identify and reduce hallucinations by 25% training-free from vision-language models.
*equal contribution